内存那些事儿----HBM和GPU算力
系列文章,欢迎阅读
内存那些事儿----基础知识I
https://www.talkwithtrend.com/Article/255113
内存那些事儿----基础知识II
https://www.talkwithtrend.com/Article/255115
内存那些事儿----内存带宽
https://www.talkwithtrend.com/Article/255545
深度学习和人工智能的兴起,必须承认GPU性能的突飞猛进起了巨大的作用,尤其是Nvidia 的GPU。Nvidia GPU的算力每一代都有提高,下图是 Nvidia V100和 A100的性能对比。

GPU算力
现在衡量GPU算力的单位都是用 TFLOPS(每秒万亿次浮点运算)。Nvidia A100 的深度学习运算性能 可达 312 TFLOPS。这样的所谓高算力实际是针对乘积累加运算的高算力。乘积累加运算(英语:Multiply Accumulate, MAC)。这种运算的操作,是将乘法的乘积结果和累加器 A 的值相加,再存入累加器:如果没有使用 MAC 指令,上述的程序需要二个指令,但 MAC 指令可以使用一个指令完成。而许多运算(例如卷积运算、点积运算、矩阵运算、数字滤波器运算、乃至多项式的求值运算,基本上全部的深度学习类型都可以对应)都可以分解为数个 MAC 指令,因此可以提高上述运算的效率。
和内存带宽的理论值一样,厂家给出的也都是GPU运算单元的理论值,而非系统的真实值,因为系统的真实值依赖于很多因素,某些极端情况下,真实值可能只有理论值的十分之一。
内存带宽
影响GPU 算力的一个重要因素就是内存带宽,这里的内存很多时候也被称作是GPU的”显存”。因为GPU集成了大量的并行运算单元,Nvidia GPU叫做 Tensor Core ,如果内存带宽跟不上,无疑会称为整个运算的瓶颈。
例如谷歌第一代TPU,理论值为90TFOPS算力,最差真实值只有1/9,也就是10TFOPS算力,因为第一代内存带宽仅34GB/s。而第二代TPU下血本使用了HBM内存,带宽提升到600GB/s(单一芯片,TPU V2板内存总带宽2400GB/s)。最新的Nvidia A100使用40GB的2代HBM,带宽提升到1600GB/s,比V100提升大约73%。
HBM-High Bandwidth Memory
常见的服务器内存条,可以被认为是平面内存,是把内存颗粒平铺开来。而且由于工艺等等的限制,平面DDR5想再提高频率已经比较难了。平面内存想获得更大的存储空间,就需要更大的面积,这对有限的空间也是一种挑战。为了追求更高的内存带宽,节约空间,业界发展出了堆叠式内存技术。最有代表性的就是 HBM 即 High Bandwidth Memory 高带宽内存技术,HBM目前量产到第二代。HBM概念图如下所示。

堆叠之后,DRAM层与层之间的访问是通过 TSV (Through Silicon Via) 即所谓 硅通孔 技术来完成。
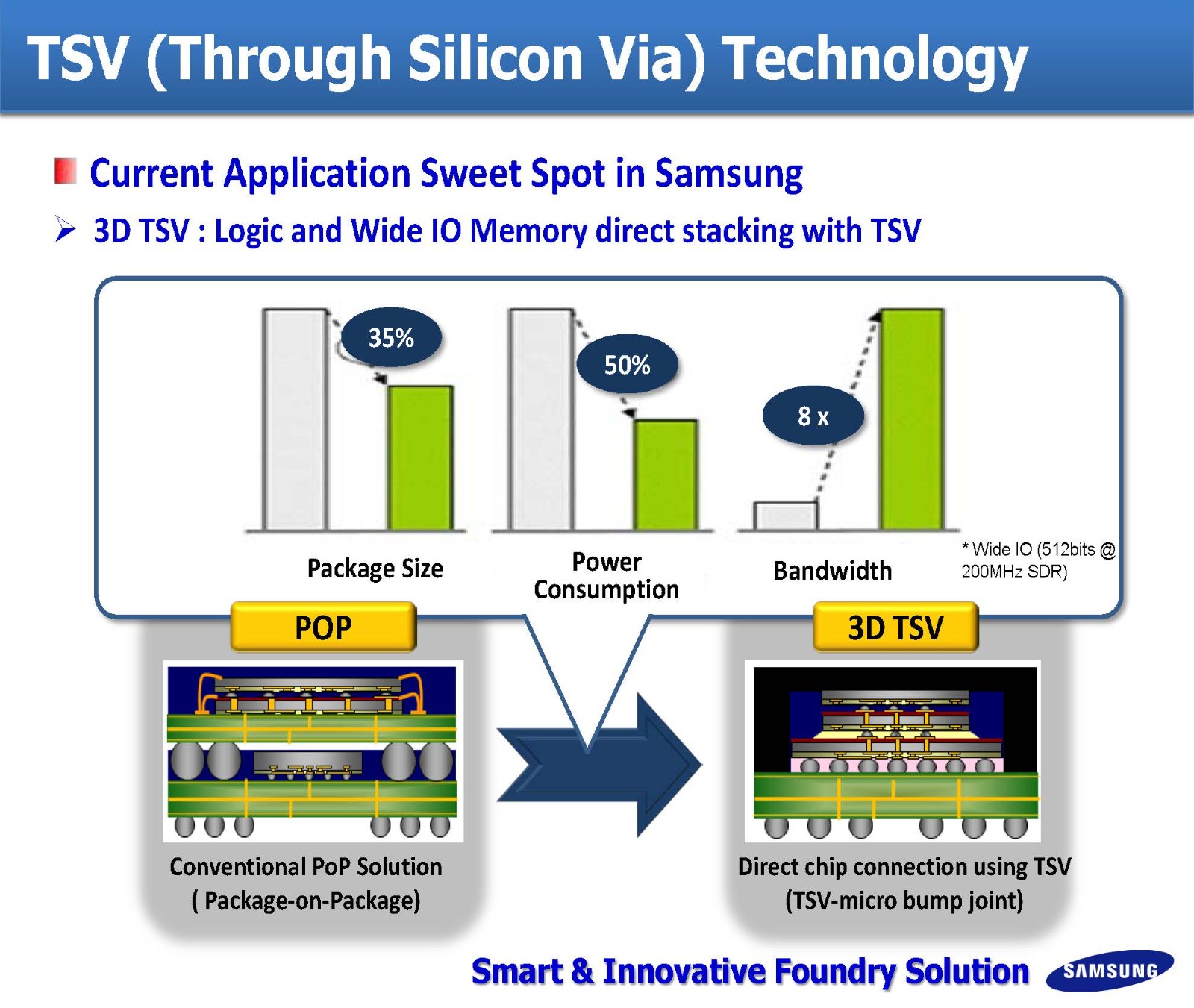
Nvidia A100 GPU 使用 80GB 的HBM2 内存,整个内存带宽可以超过 2TB/s。
HBM最早由AMD和SK Hynix提出,但是三星几乎垄断HBM市场,目前已经发展到HBM2代,HBM2可以做到最高12颗TSV堆叠3.6TB/s的带宽,传统DRAM最顶级的GDDR6是768GB/s。HBM的缺点是太贵,针对消费类市场的产品没人敢用,也缺乏应用场景,只有数据中心才用。除此之外还有一个缺点,用HBM就意味着必须用台积电的CoWos工艺,这样才能尽量缩短与运算单元的物理距离,最大限度发挥HBM的性能。英特尔的EMIB工艺可以抗衡台积电的CoWos工艺,但英特尔不做代工。因此全球高性能AI芯片无一例外都在台积电生产,市场占有率100%。
如果觉得我的文章对您有用,请点赞。您的支持将鼓励我继续创作!
赞0作者其他文章
评论 0 · 赞 0
评论 0 · 赞 0
评论 0 · 赞 0
评论 0 · 赞 0
评论 0 · 赞 0
添加新评论0 条评论